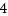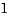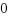mount
Rev.6を表示中。最新版はこちら。
vfsmntアドレス+ディレクトリdentryアドレスをハッシュインデックスとするmount_hashtable[]にマウントデバイスをtailリストし、マウントディレクトリdentry->d_flagにCACHE_MOUNTEDが設定され、パス検索でdentryのd_flags & DCACHE_MOUNTEDなら、mount_hashtable[]から、係るdenryのマウントデバイスを取得します。実装概略サンプル-mount dev dir
static struct list_head mount_hashtable[10];
void mount(char *dev, struct path *dir)
{
struct vfsmount *mnt;
struct list_head *head;
mnt = do_kern_mount(dev);
mnt->mnt_mountpoint = dir->dentry;
mnt->mnt_parent = dir->mnt;
head = mount_hashtable[(dir->mnt + dir->dentry) % 10];
mnt->mnt_hash->prev = head->prev;
mnt->mnt_hash->next = head;
head->prev->next = mnt->mnt_hash;
head->prev = mnt->mnt_hash;
dir.dentry->d_flags |= DCACHE_MOUNTED;
}
struct vfsmount *lookup_mnt(struct path *dir)
{
struct list_head *head
struct mount *p, *found=NULL;
if (dir->dentry->d_flags & DCACHE_MOUNTED) {
head = mount_hashtable[(dir->mnt + dir->dentry) % 10];
while () {
p = list_entry(head, struct mount, mnt_hash);
if (p->mnt_parent->mnt == dir->mnt && p->mnt_mountpoint == dir->dentry) {
found = p;
break;
}
}
}
return found;
}
mount_hashtable[]はページキャッシュを領域とする動的メモリで、要素はlist_head->next/prevのアドレスで、サイズはシステムに依存され、従ってmount_hashtable[]要素数は動的で、かかる実装は2進数によるmount_hashtable[]の要素数等の動的配列インデックスの実装となり、mount_hashtable[]の要素インデックスは2進数によるサイズ長のmnt+dentryアドレスのインデックス長に係る下位/上位を加算した値で実装されます。HASH_SHIFTはmount_hashtable[]の要素数の2進数の対数で、HASH_SIZEは実要素数となります。
#define HASH_SHIFT ilog2(PAGE_SIZE / sizeof(struct list_head))
#define HASH_SIZE (1UL << HASH_SHIFT)
struct mount {
struct list_head mnt_hash;
struct mount *mnt_parent;
struct dentry *mnt_mountpoint;
struct vfsmount mnt;
#ifdef CONFIG_SMP
struct mnt_pcp __percpu *mnt_pcp;
#else
int mnt_count;
int mnt_writers;
#endif
struct list_head mnt_mounts; /* list of children, anchored here */
struct list_head mnt_child; /* and going through their mnt_child */
struct list_head mnt_instance; /* mount instance on sb->s_mounts */
const char *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */
struct list_head mnt_list;
struct list_head mnt_expire; /* link in fs-specific expiry list */
struct list_head mnt_share; /* circular list of shared mounts */
struct list_head mnt_slave_list;/* list of slave mounts */
struct list_head mnt_slave; /* slave list entry */
struct mount *mnt_master; /* slave is on master->mnt_slave_list */
struct mnt_namespace *mnt_ns; /* containing namespace */
#ifdef CONFIG_FSNOTIFY
struct hlist_head mnt_fsnotify_marks;
__u32 mnt_fsnotify_mask;
#endif
int mnt_id; /* mount identifier */
int mnt_group_id; /* peer group identifier */
int mnt_expiry_mark; /* true if marked for expiry */
int mnt_pinned;
int mnt_ghosts;
};
void __init mnt_init(void)
{
unsigned u;
int err;
init_rwsem(&namespace_sem);
mnt_cache = kmem_cache_create("mnt_cache", sizeof(struct mount),
0, SLAB_HWCACHE_ALIGN | SLAB_PANIC, NULL);
mount_hashtable = (struct list_head *)__get_free_page(GFP_ATOMIC);
if (!mount_hashtable)
panic("Failed to allocate mount hash table\n");
printk(KERN_INFO "Mount-cache hash table entries: %lu\n", HASH_SIZE);
for (u = 0; u < HASH_SIZE; u++)
INIT_LIST_HEAD(&mount_hashtable[u]);
br_lock_init(&vfsmount_lock);
err = sysfs_init();
if (err)
printk(KERN_WARNING "%s: sysfs_init error: %d\n",
__func__, err);
fs_kobj = kobject_create_and_add("fs", NULL);
if (!fs_kobj)
printk(KERN_WARNING "%s: kobj create error\n", __func__);
init_rootfs();
init_mount_tree();
}
static int graft_tree(struct mount *mnt, struct path *path)
{
if (mnt->mnt.mnt_sb->s_flags & MS_NOUSER)
return -EINVAL;
if (S_ISDIR(path->dentry->d_inode->i_mode) !=
S_ISDIR(mnt->mnt.mnt_root->d_inode->i_mode))
return -ENOTDIR;
if (d_unlinked(path->dentry))
return -ENOENT;
return attach_recursive_mnt(mnt, path, NULL);
}
static int attach_recursive_mnt(struct mount *source_mnt,
struct path *path, struct path *parent_path)
{
LIST_HEAD(tree_list);
struct mount *dest_mnt = real_mount(path->mnt);
struct dentry *dest_dentry = path->dentry;
struct mount *child, *p;
int err;
if (IS_MNT_SHARED(dest_mnt)) {
err = invent_group_ids(source_mnt, true);
if (err)
goto out;
}
err = propagate_mnt(dest_mnt, dest_dentry, source_mnt, &tree_list);
if (err)
goto out_cleanup_ids;
br_write_lock(&vfsmount_lock);
if (IS_MNT_SHARED(dest_mnt)) {
for (p = source_mnt; p; p = next_mnt(p, source_mnt))
set_mnt_shared(p);
}
if (parent_path) {
detach_mnt(source_mnt, parent_path);
attach_mnt(source_mnt, path);
touch_mnt_namespace(source_mnt->mnt_ns);
} else {
mnt_set_mountpoint(dest_mnt, dest_dentry, source_mnt);
commit_tree(source_mnt);
}
list_for_each_entry_safe(child, p, &tree_list, mnt_hash) {
list_del_init(&child->mnt_hash);
commit_tree(child);
}
br_write_unlock(&vfsmount_lock);
return 0;
out_cleanup_ids:
if (IS_MNT_SHARED(dest_mnt))
cleanup_group_ids(source_mnt, NULL);
out:
return err;
}
static void attach_mnt(struct mount *mnt, struct path *path)
{
mnt_set_mountpoint(real_mount(path->mnt), path->dentry, mnt);
list_add_tail(&mnt->mnt_hash, mount_hashtable +
hash(path->mnt, path->dentry));
list_add_tail(&mnt->mnt_child, &real_mount(path->mnt)->mnt_mounts);
}
void mnt_set_mountpoint(struct mount *mnt, struct dentry *dentry,
struct mount *child_mnt)
{
mnt_add_count(mnt, 1); /* essentially, that's mntget */
child_mnt->mnt_mountpoint = dget(dentry);
child_mnt->mnt_parent = mnt;
spin_lock(&dentry->d_lock);
dentry->d_flags |= DCACHE_MOUNTED;
spin_unlock(&dentry->d_lock);
}
static void commit_tree(struct mount *mnt)
{
struct mount *parent = mnt->mnt_parent;
struct mount *m;
LIST_HEAD(head);
struct mnt_namespace *n = parent->mnt_ns;
BUG_ON(parent == mnt);
list_add_tail(&head, &mnt->mnt_list);
list_for_each_entry(m, &head, mnt_list)
m->mnt_ns = n;
list_splice(&head, n->list.prev);
list_add_tail(&mnt->mnt_hash, mount_hashtable +
hash(&parent->mnt, mnt->mnt_mountpoint));
list_add_tail(&mnt->mnt_child, &parent->mnt_mounts);
touch_mnt_namespace(n);
}
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
static inline unsigned long hash(struct vfsmount *mnt, struct dentry *dentry)
{
unsigned long tmp = ((unsigned long)mnt / L1_CACHE_BYTES);
tmp += ((unsigned long)dentry / L1_CACHE_BYTES);
tmp = tmp + (tmp >> hash_SHIFT);
return tmp & (HASH_SIZE - 1);
}
備考マウントデバイス数の制約はありません。メモリ取得可能範囲で無制限にmount可能です。
mnt->mnt_childのリストは、unmount/share等の親mnt下の子mntにも処理が必要となるケース故での実装です。
アドレスに係る加算は、係る領域とする配列のインデックスに相当します。
list_add_tail(&mnt->mnt_hash, mount_hashtable + hash(path->mnt, path->dentry));
mount_hashtable + hash(path->mnt, path->dentry) ===> mount_hashtable[hash(path->mnt, path->dentry)]
#include <stdio.h>
struct babakaka {
char tmp[100];
int val;
};
void main()
{
int i;
struct babakaka a[10], *b, *c;
for (i = 0; i < 10; i++) {
a[i].val = i;
}
b = a;
for (i = 0; i < 10; i++) {
c = b + i;
printf("%d:", c->val);
}
printf("\n");
}
[root@localhost mnt7]# ./a.out
0:1:2:3:4:5:6:7:8:9: