
Radix Tree
Rev.5を表示中。最新版はこちら。
1. 概要
Tree検索を行うRadix TreeのLinuxでの実装メモ。
Radix Treeの機能はlib/radix-tree.cで提供される。実際の使用例としては、ページキャッシュのページを管理するのにRadix Treeを使っている。
2. データ構造
LinuxでのRadixツリーの構造を図1に示す。
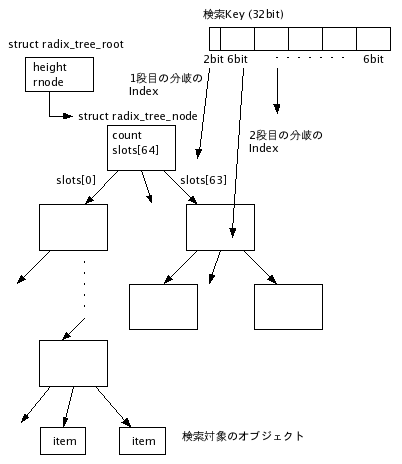
2.1 Treeの管理データ
Radix Treeの管理の大元のデータとしてstruct radix_tree_rootがある。このデータはRadix Tree関連関数でどのTreeに対して操作を行うのか指定するのに使われる。
このデータのrnodeがルートノード(Treeトップのノード)を指している。heightはTreeの高さを表しており、例えばheight=1だと、ルートノードのみの1段のTreeであることを意味する。
2.2 Treeのノード
Treeの各ノードはstruct radix_tree_nodeが使われる。
この構造体にはslots[]配列があり、子ノードへのポインタを保持している。末端のノードの場合はslots[]は検索対象のオブジェクト(item)へのポインタを格納している(*1)。子ノードやitemが無い場合はslots[]の該当要素にはNULLが格納されている。現状slots配列は64エントリ存在し、Radix Treeは64分木を構成することになる。
countフィールドは、そのノードに子がいくついるかを示すカウンタ。つまり、slots[]に有効なポインタがいくつ格納しているかを表している。
(*1) ページキャッシュのRadix Treeの場合は、itemはstruct pageになる。
2.3 検索キー
Tree検索時に使用する検索キー(index)はLinuxではunsigned long(32bit)値に限定されている。
検索キーは図1に示すようにRADIX_TREE_MAP_SHIFT(6) bit毎に区切られて扱われる。検索キーの区切られた各部分の値がTree各段のノードのslots[]のインデクスとなる(*2)。検索時は各フィールドの値を参照してTreeを下っていくことで、検索キーに対応するitemを取得できる。
[補足]
6bit区切りだと端数がでるので、検索キーの上位は2bitのみになる。このため、図1では1段目でも64分岐するように描いているが、実際には4分岐しかしない。
ページキャッシュのRadix Treeではページ(struct page)を登録する際、ファイル先頭からのページオフセットをindexにしている。このため、アクセスするデータのページオフセットから高速にページデータを取得できる。
3. Treeの拡張
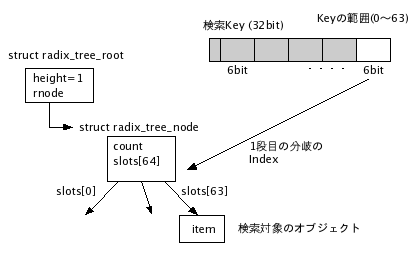
図1ではRadix Treeの高さが固定であるような描き方になっているが、実際にはRadix Treeの高さはエントリを追加した時に必要に応じて拡張されていくようになっている。
例えば、登録エントリの検索キーが0〜63の範囲に収まっている時は、Treeは1段しかない(図2)。
ここで、検索キーが2000のエントリがRadix Treeに追加されると、Treeが2段必要になる。このため、Treeが1段拡張される(図3)。このように、Treeに登録されているエントリの検索キーの範囲に応じてTreeの高さが拡張される。
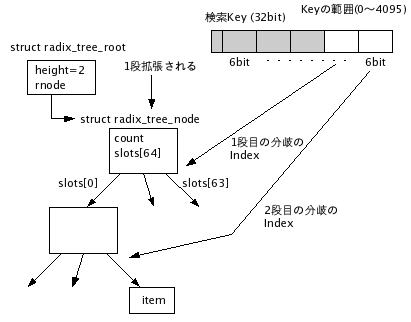
図3 2段に拡張されたRadix Tree
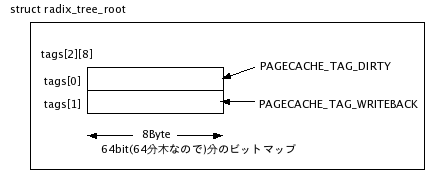
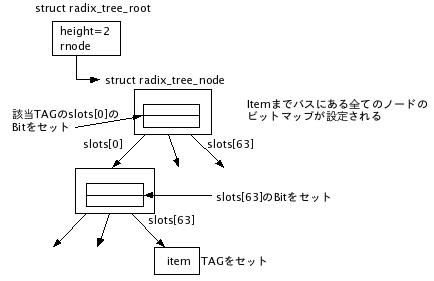
4. タグ
関連関数
radix_tree_insert(*root, index, *item)radix_tree_lookup(struct radix_tree_root *root, unsigned long index)
rootで指定したTreeをindexで検索して、itemが存在すれば返す。
{kind=link}
{kind=link}