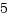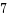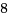CPU変数のページフレームキャッシュ
1ページの取得は、CPU変数のページフレームキャッシュから取得しているようです。1ページおよび複数ページの獲得は、alloc_pages関数で処理されます。(1ページの場合マクロでorder=0としてコール)alloc_pages関数はバディシステムからページを獲得します。しかしオーダが0の時、CPU変数で管理されるページフレームから獲得されます。そこにフレームが無かったら、わざわざバディシステムからフレームをCPU変数に繋ぎ変えて取得します。
なぜこのような事をするかと言う事ですが、私なりの理解では、CPU変数下で管理することは、一時期であるにしても、そのページに関しては他のCPUから使われることがない。ということです。そうなるとハードキャッシュの兼ね合いでパフォーマンスがあがるのだろうと。なんとなく理解しました。(なぜ?となると、ハード周りのことが無知で、今ひとつ分かりません。)
で、この辺りの処理を見てみる事にしました。物理ページフレームが必要と思われる処理でfsl_diu_alloc関数は、ビデオ関係のメモリを獲得する処理のようです。獲得するバイト数(フレーム数でない。)で、alloc_pages_exact関数をコールします。
そのorderを引数で__get_free_pages関数を、ここでばバディシステムからページフレームを獲得し、その仮想アドレスを返します。獲得した連続する先頭のページフレームのアドレスです。alloc_end = addr + (PAGE_SIZE << order)で獲得したページフレームの終端アドレスをセットします。used = addr + PAGE_ALIGN(size)は実際必要とする終端アドレスです。used < alloc_endで、不必要なメモリーをページ単位でfree_page関数で戻しています。
なぜこのような事をするかと言う事ですが、私なりの理解では、CPU変数下で管理することは、一時期であるにしても、そのページに関しては他のCPUから使われることがない。ということです。そうなるとハードキャッシュの兼ね合いでパフォーマンスがあがるのだろうと。なんとなく理解しました。(なぜ?となると、ハード周りのことが無知で、今ひとつ分かりません。)
で、この辺りの処理を見てみる事にしました。物理ページフレームが必要と思われる処理でfsl_diu_alloc関数は、ビデオ関係のメモリを獲得する処理のようです。獲得するバイト数(フレーム数でない。)で、alloc_pages_exact関数をコールします。
static void *fsl_diu_alloc(size_t size, phys_addr_t *phys)
{
void *virt;
virt = alloc_pages_exact(size, GFP_DMA | __GFP_ZERO);
if (virt) {
*phys = virt_to_phys(virt);
pr_debug("virt=%p phys=%llx\n", virt,
(unsigned long long)*phys);
}
return virt;
}
alloc_pages_exact関数で獲得サイズを、get_order関数で2のオーダに変換しています。get_order関数ではsizeをページ数に変換しています。ポイントは(size - 1) >> (PAGE_SHIFT - 1)で、余った分も1ページとなるようにしていることです。それをループでsize >>= 1(2で割ること)しながら、sizeが0になるまでorder++でオーダを取得しています。そのorderを引数で__get_free_pages関数を、ここでばバディシステムからページフレームを獲得し、その仮想アドレスを返します。獲得した連続する先頭のページフレームのアドレスです。alloc_end = addr + (PAGE_SIZE << order)で獲得したページフレームの終端アドレスをセットします。used = addr + PAGE_ALIGN(size)は実際必要とする終端アドレスです。used < alloc_endで、不必要なメモリーをページ単位でfree_page関数で戻しています。
void *alloc_pages_exact(size_t size, gfp_t gfp_mask)
{
unsigned int order = get_order(size);
unsigned long addr;
addr = __get_free_pages(gfp_mask, order);
if (addr) {
unsigned long alloc_end = addr + (PAGE_SIZE << order);
unsigned long used = addr + PAGE_ALIGN(size);
split_page(virt_to_page(addr), order);
while (used < alloc_end) {
free_page(used);
used += PAGE_SIZE;
}
}
return (void *)addr;
}
static __inline__ __attribute_const__ int get_order(unsigned long size)
{
int order;
size = (size - 1) >> (PAGE_SHIFT - 1);
order = -1;
do {
size >>= 1;
order++;
} while (size);
return order;
}
free_page関数はオーダ0のfree_pages関数です。order == 0の時free_hot_page関数で、CPU変数のフレームキャッシュの戻すことになります。(__free_pages_ok関数はバディシステムに戻しているよう・・・)
#define free_page(addr) free_pages((addr),0)
void __free_pages(struct page *page, unsigned int order)
{
if (put_page_testzero(page)) {
if (order == 0)
free_hot_page(page);
else
__free_pages_ok(page, order);
}
}
free_hot_page関数は引数を0にしてfree_hot_cold_page関数をコールし、活性化フレームキャシュに戻します。非活性に戻す場合は1でfree_hot_cold_page関数をコールします。
void free_hot_page(struct page *page)
{
free_hot_cold_page(page, 0);
}
void free_cold_page(struct page *page)
{
free_hot_cold_page(page, 1);
}
で、ここからが本題となります。pcp = &zone_pcp(zone, get_cpu())->pcpで、CPU毎に管理しているper_cpu_pages *pcpを取得し、それにリスト登録しているだけのようです。注目すべき点は活性/非活性とも同じリストに登録していることです。活性化の時は先頭に、非活性の時は末尾という具合です。なお以降はページフレームキャッシュに所定のフレームが無い場合、バヂィシステムから補充するためのものです。
#define zone_pcp(__z, __cpu) ((__z)->pageset[(__cpu)])
static void free_hot_cold_page(struct page *page, int cold)
{
struct zone *zone = page_zone(page);
struct per_cpu_pages *pcp;
unsigned long flags;
:
:
pcp = &zone_pcp(zone, get_cpu())->pcp;
local_irq_save(flags);
__count_vm_event(PGFREE);
if (cold)
list_add_tail(&page->lru, &pcp->list);
else
list_add(&page->lru, &pcp->list);
set_page_private(page, get_pageblock_migratetype(page));
pcp->count++;
if (pcp->count >= pcp->high) {
free_pages_bulk(zone, pcp->batch, &pcp->list, 0);
pcp->count -= pcp->batch;
}
local_irq_restore(flags);
put_cpu();
}
活性化、非活性化とハードウエアーに密接している処理のようですが、ただリストの前から使用することで、キャッシュ上に載っている可能性が高いからそれを使ったほうがいいんじゃないの。というレベルのようです。