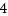メモリーマップ
Rev.3を表示中。最新版はこちら。
通常のファイル読み書きは、openでファイル構造体を取得し,read/writeでユーザのメモリー空間とのやりとりを行う。ファイルとのデータは、IOブロック層に渡って、実際の物理デバイスへとなるのだが、IOブロック層は、ユーザで渡されたデータ(open/writeの引数)と直接やりとりを行うものでない。IOブロック層はページキャッシュと、そして、ユーザへはこのページキャッシュを通してやり取りする。実際read/write処理では,まずinode->page_treeのradix-treeでリストされるページキャッシュに、目的とするデータが存在するか確認する。なければページを割り当て、このinode->page_treeのradix-treeに追加して、このページへ物理デバイス上のデータを読み込んだのち、(ページキャッシュがあるなら物理デバイスから読み込む必要はない。)ページキャッシュとユーザ空間のメモリー領域とやり取りする。直接ユーザのバッファーとIOブロック層とでやり取りしたほうがいいように思えるが、ページキャッシュという名の通り、次回の読み込みで、再度物理デバイスとやり取りしないための工夫である。また書き込み処理で、ユーザプロセスとしては、対応するページキャッシュに書き込むことで完了する。実際の物理デバイスへの書き込みは、カーネルがある種の条件のもとでユーザプロセスのあずかり知らぬところで処理してくれるといった具合である。
メモリーマップとは、このページキャッシュをバイパスして直接ユーザのバッファーとIOブロック層とでやりとりしようというものだ。でも、そしたらキャッシュの恩恵がなくなるのでは?と・・・。
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <errno.h>
#include <fcntl.h>
#include <sys/mman.h>
int main()
{
int i, fd;
unsigned char *p;
fd=open("abc",O_RDONLY);
p=mmap(0,10,PROT_READ,MAP_SHARED,fd,0);
for (i = 0; i < 10; i++) {
printf("%c", *p++);
}
printf("\n");
munmap(p,10);
close(fd);
}
[root@KURO-BOXHG kitamura]# cat abc
abcdefghijklmn
[root@KURO-BOXHG kitamura]# ./a.out
abcdefghij
ユーザ空間のメモリーとは、プロセス構造体task_struct->mm_struct->vm_area_structのリージョンで管理される領域のことである。ユーザプログラムのreadで渡されるバッファー領域も、このvm_area_struct内のメモリー空間となる。そうすればキャッシュメモリをユーザプロセスのvm_area_structでも管理させればいいではないか。というのがメモリーマップの考え方だ。通常のメモリーリージョンならNULLであるvm_area_struct->fileに、メモリーマップされているファイルオブジェクトを設定する。vm_area_struct->fileがNULLでないなら、この領域はメモリマップされている。ということだ。従って、そこからファイルのinodeが取得され、メモリーマップ読み込みのinodeのコールバック関数へと処理される。
mmapを実行すると、実ページアドレスは実際のアクセスあるまで遅延されるが、指定されたメモリーサイズに応じたメモリーリージョンがvm_area_structに作成される。そして実際のアクセスに応じて、inodeのキャッシュをinodeのキャッシュリストとvm_area_structに登録していく。(たぶん)
mmapは内部的にメモリーを確保して、通常のreadすることで実現する、ファイル読み込み簡易バージョンという位置づけでなく、内部実装に相違に基づく処理といえる。途中のページキャッシュからユーザ空間への転送処理がなくなる分間違いなくパフォーマンスはよくなる。しかし、いきなり大きなファイルをそのサイズでmmapすると・・・。ページキャッシュは、元ファイルから読み込んだらいいわけで、スワップする必要がない。mmapのバッファー空間はユーザ空間ということでスワップ対象なる。かえって、スワップが発生してしまいパフォーマンス低下の要因になってしまいそうだ。