
送受信
Rev.52を表示中。最新版はこちら。
1. 受信処理
1.1 従来の受信処理
ネットワークインタフェースで受信したパケットは、デバイスドライバのH/W割り込み処理処理で刈り取られる。デバイスドライバは受信したパケットをカーネルの受信キューに積み、ソフトウェア割り込みを発生させる。
受信ソフトウェア割り込みのハンドラは、受信キューに積まれているパケットを取りだし該当プロトコルの受信ハンドラを呼び出す。
デバイスドライバの受信処理が受信キューにパケットを積むだけで、受信処理のメインはソフトウェア割り込み処理で実装しているのは、H/W割り込みの処理を極力短くしてシステムのレスポンスを向上させるため。
受信処理の流れを図1に示す。

図1 NAPI未対応の受信処理
2. ソフトウェア割込みを発生させる際、poll_listには仮想的なnet_device(backlog_dev)をチェーンする。backlog_deviceのポーリングルーチンにはprocess_backlog()が指定されているので、受信ソフトウェア割込みでpoll_listに登録されているデバイスのポーリングルーチンを呼び出すとprocess_backlog()が呼び出される。
3. Kernel2.6ではネットワークの受信処理として、ハードウェア割込みベースの本方式からポーリングベースの方式(NAPI)が使われるようになった。NAPIではpoll_listにはパケットを受信してポーリングが必要なnet_deviceがチェーンされている。本方式を見ただけではpoll_listやdev->poll()など、ポーリングしていないのになぜ「ポーリング」なのか意味不明だが、NAPIの受信処理を共通化するためこのようになっている。NAPIについては後述。
1.2 NAPI対応の受信処理
従来の受信処理ではパケット受信の度にハードウェア割込みを処理しなければならないため、受信負荷が高い場合にシステムが重くなる問題があった。Kernel2.6ではデバイスドライバに対してNAPI(New API)と呼ばれる新しい受信APIが提供されるようになった。
NAPIに対応した受信処理ではパケットを受信してハードウェア割込みが発生すると、H/W割込みを禁止してポーリング処理によってデバイスの受信バッファからパケットを取り出していく。バッファが空になって受信処理が完了すると割込みを再度許可状態にして、次の受信が発生するのを待つようにしている。
NAPI対応の受信処理を図2に示す。
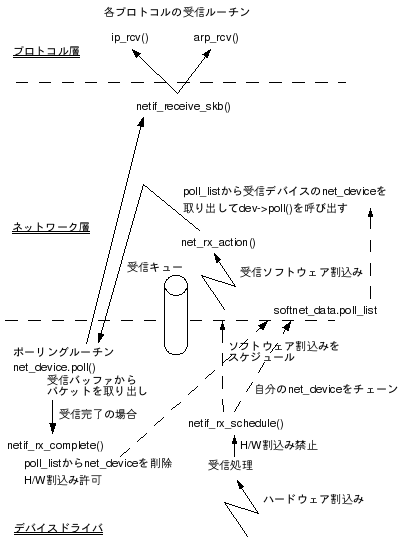
2. 受信ソフトウェア割込みでは、poll_listからポーリングが必要なデバイスを取り出し、デバイスドライバのポーリングルーチンを呼び出す(dev->poll())。(ポーリングルーチンの例:e100.c::e100_poll())
3. ドライバのポーリングルーチンはデバイスの受信バッファからパケットを取り出して、netif_receive_skb()に渡していく。受信バッファが空になったら、netif_rx_complete()を呼び出して受信処理を完了させる。netif_rx_complete()はpoll_listからnet_deviceを削除して、H/W割込みを許可状態にする。
4. 以上のようにNAPIではsoftnet_dataの受信キューは使用されない(はず)。
1.3 関連関数
netif_rx(skb)受信パケットを受信キューに積む。
キューに積む際、キューの長さがnetdev_max_backlog(backlog:残務)を越えていた場合はパケットを廃棄する。キューが空の状態でパケットをキューに積んだ場合は、 netif_rx_schedule()で受信ソフトウェア割り込み(NET_RX_SOFTIRQ)を発生させる。
netif_rx_schedule()
netif_rx_complete()
poll_listからnet_deviceを削除して、ネットワークデバイスを割込み許可状態に戻す。
net_rx_action()
受信キューからパケットを取りだし、プロトコルの受信処理を呼び出す。
/* 自CPUのsoftnet_dataを取得 */ *queue = &__get_cpu_var(softnet_data); while (!list_empty(&queue->poll_list)) { /* poll_listからポーリング(受信処理)が必要な * インタフェースを取得 (*1) */ dev = list_entry(queue->poll_list.next, struct net_device, poll_list); /* ドライバのポーリングルーチン(dev->poll()) * を呼び出してパケット刈り取り (*2) */ if (dev->quota <= 0 || dev->poll(dev, &budget)) { /* キューの受信パケットを一部だけ処理した */ /* net_deviceをpoll_listの後ろにチェーンしなおして * 後で再開する */ } else { /* キューの受信パケットを全て処理した */ } } return;
(*2) NAPI未対応ドライバの場合はdev->poll()はprocess_backlog()を呼び出すことになる。初期化ルーチンnet_dev_init()でqueue->backlog_dev.pollにはprocess_backlogが登録されている。
process_backlog()
受信キューからパケットを取り出し、netif_receive_skb()へ渡す。一回の受信処理の負荷が高い場合は途中で中断して-1を返す。
for (;;) {
/* 自CPUの受信キューからパケット取り出し */
skb = __skb_dequeue(&queue->input_pkt_queue);
if (!skb)
goto job_done; /* キューが空。受信完了 */
netif_receive_skb(skb);
work++;
/* 処理したパケット数がQuotaを越えたか
* 受信処理に時間がかかったら一旦中断 */
if (work >= quota || jiffies - start_time > 1)
break;
}
return -1;
job_done:
/* 受信が完了したのでpoll_listからbacklog_devを削除 */
list_del(&backlog_dev->poll_list);
return 0;
netif_receive_skb()
ARP - arp_rcv()
IPv6 - ipv6_rcv()
: : /* ETH_P_ALL(全パケット種別)で登録されている * エントリがあれば受信ハンドラを呼び出す。(*1) */ list_for_each_entry_rcu(ptype, &ptype_all, list) { if (!ptype->dev || ptype->dev == skb->dev) { if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); /* (*2) */ pt_prev = ptype; } } handle_diverter(skb); /* Bridge処理 * Bridge動作をするようにカーネルが * コンパイルされていなければなにもしない */ if (handle_bridge(&skb, &pt_prev, &ret, orig_dev)) goto out; /* プロトコルタイプ(MACヘッダのTypeフィールドの値) */ type = skb->protocol; /* * 該当プロトコルの受信ルーチンを呼び出す */ list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type)&15], list) { if (ptype->type == type && (!ptype->dev || ptype->dev == skb->dev)) { if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); /* (*2) */ pt_prev = ptype; } } if (pt_prev) { ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev); } else { kfree_skb(skb); /* Jamal, now you will not able to escape explaining * me how you were going to use this. :-) */ ret = NET_RX_DROP; }
(*2) deliver_skb()はpt_prev->func()(プロトコルの受信ルーチン)を呼び出す。
2. 送信処理
2.1 処理の流れ
送信処理の流れを図3に示す。
プロトコル層はdev_queue_xmit()でパケットを送信する。dev_queue_xmit()はパケットをデバイスの送信キュー(dev->qdisc)に積んでqdisc_run()を呼び出す。qdisc_run()はキューの状態をチェックした後、qdisc_restart()を呼び出す。qdisc_restart()は送信キューからパケットを取り出し、デバイスドライバの送信ルーチンを呼び出す(dev->hard_start_xmit())。最後にnetif_schedule()を呼び出して送信割込みを発生させる。
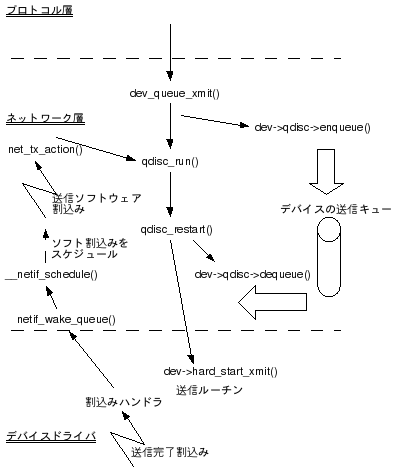
2.2 スケジューラ
送信キューにはスケジューラが存在する。このため、キューに積む時(dev->qdisc->enqueue())にスケジューラの種類に応じてパケットが並び替えられる。
スケジューラはdev_activate()でデバイスを活性化する時に設定される。デフォルトのスケジューラは"pfifo_fast"。このスケジューラは単純なFIFOでパケットの並び替えは行わない。"pfifo_fast"の場合、dev->qdisc->enqueue()はpfifo_fast_enqueue()を呼び出すことになる。
各スケジューラで使用される関数はstruct Qdisc_opsで定義される。
2.3 関連関数
dev_queue_xmit()- 送信キューに積む
デバイスのQueue(skb->dev->qdisc)にデータを積む
qdisc_restart()
net_tx_action()
netif_schedule()
dev_kfree_skb_any()
通常はdev_kfree_skb()でskbを解放するが、IRQ(H/W割込み)コンテキストだった場合は、dev_kfree_skb_irq()を呼ぶ。dev_kfree_skb_irq()はskbをcompletion_queueに積んで、送信ソフトウェア割込みを発生させる。この時点ではskbの解放処理は行われない。completion_queueに積まれたskbは送信ソフトウェア割込み処理(net_tx_action())で解放される。このようになっているのは、skbの解放はIRQコンテキストではNon-Safeであるため。
3. 関連データ
3.1 キュー
ネットワーク層とデバイスドライバ層でデータをやり取りするのにstruct softnet_dataがある。受信キューもこの中にある。softnet_dataはCPU毎に存在し、net/core/dev.cで以下のように定義されている。struct softnet_dataのフィールドを表1に示す。
DEFINE_PER_CPU(struct softnet_data, softnet_data) = { NULL };
|
フィールド |
説明 |
|---|---|
|
output_queue |
送信中のネットワークデバイス(struct net_device)がチェーンされる。 |
|
input_pkt_queue |
受信キュー。デバイスドライバによって受信パケットが積まれ、受信ソフトウェア割り込みでプロトコルの受信処理に渡される。 |
|
poll_list |
受信処理中のネットワークデバイス(struct
net_device)がチェーンされる。受信ソフトウェア割込みで、本リストに連なっているnet_deviceのポーリングルーチン(dev->poll())を呼び出して受信パケットを刈り取っていく。デバイスドライバがnetif_rx_schedule()で受信割込みを発生させる際にチェーンされる。 ドライバがNAPI未対応(netif_rx()を使う)の場合は、ここにはbacklog_devがつながれる。 |
|
completion_queue |
デバイスドライバがパケット送信完了後などにskbを解放する際、IRQ(H/W割込み)コンテキストであった場合、skbを本キューに一旦積んで後で解放する。 dev_kfree_skb_any()参照。 |
|
backlog_dev |
NAPI未対応ドライバがnetif_rx()でパケットをネットワーク層に渡す際に使用される仮想的なnet_device。poll_listに積まれる。本デバイスのポーリングルーチンはprocess_backlog()。 |
3.2 受信ルーチンの登録
各プロトコルは初期化時に受信ルーチンの登録を行う。受信ルーチンの登録はdev_add_pack()でstruct packet_typeを登録することにより行う。struct packet_typeにはプロトコルタイプ(MACヘッダのTypeフィールドの値)と受信ハンドラへのポインタが格納されており、受信時にパケットのTypeをチェックしてマッチするエントリの受信ルーチンを呼び出すことで、パケットを各プロトコルの受信ルーチンに振り分けている。
packet_typeは以下のようにして管理される。
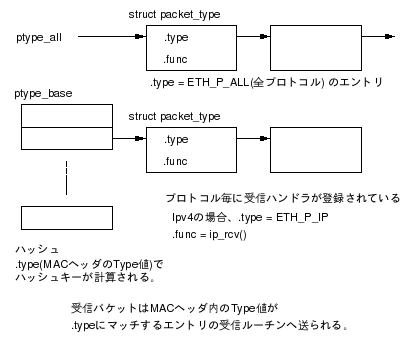
packet_typeはptype_allとptype_baseに分けて管理される。ptype_allには.typeがETH_P_ALL(全プロトコルが対象)であるpacket_typeが登録される。ptype_baseには.typeに個別のプロトコルが指定されたエントリが登録される。ptype_baseはハッシュテーブルになっており、Type値を元にハッシュキーが計算される。
関連ドキュメント
Documentation/networking/NAPI_HOWTO.txt