
物理ページ管理
Rev.22を表示中。最新版はこちら。
Buddy Systemに関するメモ。
Buddy Systemでは、物理ページ単位のメモリの割り当てを管理する。
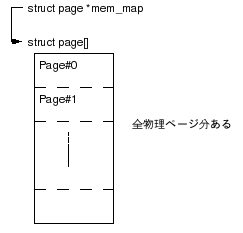
mem_mapが指す先に全物理ページのstruct pageが並んでいる。Pageフレーム0から順番に並んでいるのでページフレーム番号が配列のインデックスとなる。(i386で1Page 4KBの場合 物理アドレス >> 12)
struct pageのvirtualフィールド
実際に物理メモリがどのようにZoneに分けられているかは起動時のログで確認できる。
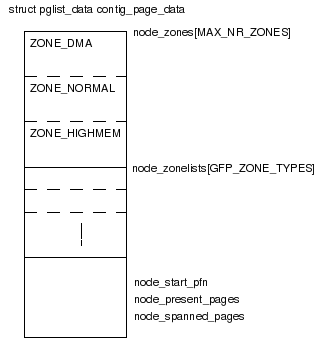
まずシステムの連続した物理ページを管理する構造体contig_page_dataがある。この中に各Zone毎の情報を保持するnode_zones[]がある。
[フィールドに関するメモ]
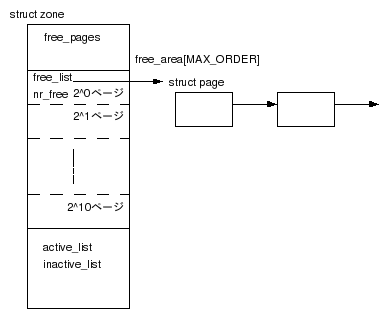
node_zones[]の各要素では各Zone内の物理ページに関するFreeListがある。物理ページはあらかじめ2^0〜2^10ページの11種類の大きさに分けて管理されている。free_area[]に各大きさ毎にFreeListがありstruct pageをチェーンしている。alloc_pages()でページを割り当てると、該当サイズのFreeListからpageが返される。
なお、ここで管理されている2^nページは物理的に連続したページとなっている。
[フィールドに関するメモ]
(*1) 1ページ取得の場合は、FreeListでなく自CPUのリストからページを取得している。リストが空の時はFreeListからまとまったページ数を移動してから、取得している。CPU毎にリストを持っているのは、ページ取得の際にSpinLockを省くためだと思われる。
PF_MEMALLOC:rebalanceのtry_to_free_pages()の無限ループにならないようにするためのフラグ。このフラグが立っていたらrebalance:のtry_to_free_pages()の延長で動作しているので、rebalance:の方に処理が流れないようにしている。
TIF_MEMDIE:OOM(Out On Memory)でkillされて、プロセスが終了処理中であることを示す。プロセスのkillを確実に行うため、ここでWaterMarkを無視してメモリを確保しようとしている。
空きメモリ管理に関する初期化
[関連関数]
alloc_pages(gfp_mask, order)
config_page_data,mem_mapへのマクロ
#define NODE_DATA(nid) (&contig_page_data)
#define NODE_MEM_MAP(nid) mem_map
Buddy Systemでは、物理ページ単位のメモリの割り当てを管理する。
1. 物理ページの管理
システムが持つ物理ページは1ページ毎に対応するstruct page構造体があり、管理されている。alloc_pages()等でページを割り当てた場合は、該当ページのstruct pageが返されるようになっている。mem_mapが指す先に全物理ページのstruct pageが並んでいる。Pageフレーム0から順番に並んでいるのでページフレーム番号が配列のインデックスとなる。(i386で1Page 4KBの場合 物理アドレス >> 12)
図1 全物理ページ管理データ
struct pageのvirtualフィールド
virtualフィールドは該当ページに対応するカーネル仮想アドレスを示す。
これは、0xc0000000からのストレートマップされる領域へのアドレスとなる(0xc0000000 + 物理アドレス)。memmap_init()で初期化している。
このフィールドはKernel2.6ではarchによっては存在しない。virtualがない場合、page_address()はpage - mem_mapからページフレーム#を求め物理アドレスを計算し、0xc0000000を加えてカーネル仮想アドレスを取得する。
これは、0xc0000000からのストレートマップされる領域へのアドレスとなる(0xc0000000 + 物理アドレス)。memmap_init()で初期化している。
このフィールドはKernel2.6ではarchによっては存在しない。virtualがない場合、page_address()はpage - mem_mapからページフレーム#を求め物理アドレスを計算し、0xc0000000を加えてカーネル仮想アドレスを取得する。
2. Zone
物理メモリはアドレス領域によってZoneと呼ばれる種類に分けて管理される。ページの割り当てを要求する時は、どこのZoneのページを取得するか指定することができる。表1 Zone種別
| Zone種別 | 説明 |
|---|---|
| ZONE_DMA | 先頭から16MBの物理ページ。デバイスのDMAなどで使用される。DMAは低位の物理アドレスしか使えないデバイスがあるので物理メモリ先頭に配置されている。 |
| ZONE_NORMAL | LowMemory領域の物理ページ。 ZONE_DMA以降の880MBがZONE_NORMALとなる。この領域はカーネルのアドレス空間から物理ページへストレートにマッピングされている。 |
| ZONE_HIGHMEM | HighMemory領域の物理ページ。 ZONE_NORMAL以降のページ(先頭から896MB以降)。 HighMemoryはユーザープロセスのデータやPageCacheに使われる。 |
実際に物理メモリがどのようにZoneに分けられているかは起動時のログで確認できる。
物理ページのZone分け(dmesg)
BIOS-provided physical RAM map:
BIOS-e820: 0000000000000000 - 000000000009d000 (usable)
BIOS-e820: 000000000009d000 - 00000000000a0000 (reserved)
BIOS-e820: 00000000000e0000 - 0000000000100000 (reserved)
BIOS-e820: 0000000000100000 - 000000005ffd0000 (usable)
BIOS-e820: 000000005ffd0000 - 000000005ffde000 (ACPI data)
BIOS-e820: 000000005ffde000 - 0000000060000000 (ACPI NVS)
BIOS-e820: 00000000ffb80000 - 0000000100000000 (reserved)
639MB HIGHMEM available.
896MB LOWMEM available.
found SMP MP-table at 000ff780
On node 0 totalpages: 393168
DMA zone: 4096 pages, LIFO batch:1
Normal zone: 225280 pages, LIFO batch:31
HighMem zone: 163792 pages, LIFO batch:31
3. 空きページの管理
空きメモリはZone毎に管理される。まずシステムの連続した物理ページを管理する構造体contig_page_dataがある。この中に各Zone毎の情報を保持するnode_zones[]がある。
図2 contig_page_data
[フィールドに関するメモ]
node_start_pfn:開始ページフレーム番号
node_spanned_pages: システムの持つ全ページ数
node_zones[]の各要素では各Zone内の物理ページに関するFreeListがある。物理ページはあらかじめ2^0〜2^10ページの11種類の大きさに分けて管理されている。free_area[]に各大きさ毎にFreeListがありstruct pageをチェーンしている。alloc_pages()でページを割り当てると、該当サイズのFreeListからpageが返される。
なお、ここで管理されている2^nページは物理的に連続したページとなっている。
図3 各ZoneのFreeList
[フィールドに関するメモ]
free_pages:このZone内の空きページ数
pageset[NR_CPUS]:PerCPUPageset。CPU毎のページリスト。(*1)
active_list:Activeページのリスト
inactive_list:Inactiveページのリスト
zone_mem_map:Zone先頭Pageのstruct pageへのポインタ
zone_start_pfn:Zone先頭Pageのページフレーム番号
pageset[NR_CPUS]:PerCPUPageset。CPU毎のページリスト。(*1)
active_list:Activeページのリスト
inactive_list:Inactiveページのリスト
zone_mem_map:Zone先頭Pageのstruct pageへのポインタ
zone_start_pfn:Zone先頭Pageのページフレーム番号
(*1) 1ページ取得の場合は、FreeListでなく自CPUのリストからページを取得している。リストが空の時はFreeListからまとまったページ数を移動してから、取得している。CPU毎にリストを持っているのは、ページ取得の際にSpinLockを省くためだと思われる。
4. 実装
4.1 ページの割り当て
alloc_pages()
alloc_pages()
alloc_pages_node()
Zoneの指定:
NODE_DATA(nid)->node_zonelists + (gfp_mask &
GFP_ZONEMASK)
__alloc_pages()
__alloc_pages()
__alloc_pages()(*1)
restart:
/* FreeListからページを取得 */
page = get_page_from_freelist()
if (page)
goto got_pg;
/* ページが取れなかった場合 */
wakeup_kswapd() - kswapdをwakeupして空きページを作る
alloc_flagsの設定
/* 再度ページ取得を試みる */
page = get_page_from_freelist()
if (page)
goto got_pg;
if (((p->flags & PF_MEMALLOC) ||
unlikely(test_thread_flag(TIF_MEMDIE))) &&
!in_interrupt()) {
/* 現在が割り込みコンテキストでなく
* カレントプロセスにPF_MEMALLOCかTIF_MEMDIEが立っていた場合。
* watermarkはチェックせずとにかくメモリを確保を試みる。
* (*1)
*/
if (!(gfp_mask & __GFP_NOMEMALLOC)) {
nofail_alloc:
/* WaterMarkのチェックなしでメモリ確保 */
page = get_page_from_freelist(,ALLOC_NO_WATERMARKS);
if (page)
goto got_pg;
if (gfp_mask & __GFP_NOFAIL) {
/* Waitしてリトライ(取得できるまで) */
blk_congestion_wait(WRITE, HZ/50);
goto nofail_alloc;
}
}
goto nopage;
}
/* wait不可(__GFP_WAIT指定がない)ならページ取得を諦める */
if (!wait)
goto nopage;
/*
* 以下ではtry_to_free_pages()でキャッシュなど
* 解放できるものがあれば解放する
* Dirtyページのディスクへの書きだしが発生した場合は
* プロセスがブロックする可能性がある。
*/
rebalance:
p->flags |= PF_MEMALLOC; 無限再帰呼び出し防止用のフラグ
try_to_free_pages() - ページを解放する
p->flags &= ~PF_MEMALLOC;
if (did_some_progress) {
/* try_to_free_pages()である程度メモリが解放された */
page = get_page_from_freelist();
if (page)
goto got_pg;
} else if ((gfp_mask & __GFP_FS) && !(gfp_mask
& __GFP_NORETRY)) {
page = get_page_from_freelist();
if (page)
goto got_pg;
out_of_memory(); - どれかプロセスを選んで強制終了
goto restart;
}
nopage:
got_page:
PF_MEMALLOC:rebalanceのtry_to_free_pages()の無限ループにならないようにするためのフラグ。このフラグが立っていたらrebalance:のtry_to_free_pages()の延長で動作しているので、rebalance:の方に処理が流れないようにしている。
TIF_MEMDIE:OOM(Out On Memory)でkillされて、プロセスが終了処理中であることを示す。プロセスのkillを確実に行うため、ここでWaterMarkを無視してメモリを確保しようとしている。
get_page_from_freelist()
get_page_from_freelist()
do {
if (!(alloc_flags & ALLOC_NO_WATERMARKS)) {
/* Water Markのチェック */
if (!zone_watermark_ok())
/* Water Markを下回っている */
if (!zone_reclaim_mode ||
/* 解放可能なページは解放 */
!zone_reclaim(*z, gfp_mask, order))
continue;
}
page = buffered_rmqueue(); - FreeListからページ取得
if (page) {
break;
}
} while (*(++z) != NULL); ページが取れなかったら次のZoneへ
bufferd_rmqueue()
buffered_rmqueue() - 指定ZoneのFreeAreaからpageを取得
if (likely(order == 0)) {
/* 要求ページが1ページ */
if (!pcp->count) {
/* 自CPUのPerCPUPageリストにPageがない */
/* FreeListからページを取得してPerCPUPageリストにつないでおく */
rmqueue_bulk()
}
PerCPUPageリストからPageを取得
} else {
__rmqueue() - 指定ZoneのFreeAreaからpageを取得
expand()
取得したページが指定サイズよりも大きかったら
半分に分割して、残りを該当サイズのFreeAreaに戻す。
指定サイズになるまで繰りかえす。
}
__GFP_ZERO等のフラグが設定されていたら0初期化するなど対応処理を実施
4.2 初期化処理
ページテーブルの設定pagetable_init()max_low_pfn:RAMの最後の物理ページ番号
:
kernel_physical_mapping_init() - PageTableを設定
仮想アドレス0xc0000000〜max_low_pfn*PAGE_SIZE+PAGE_OFFSETを
物理アドレス0x00000000へストレートマッピング
:
e820hのBIOSコールで取得したメモリマップから計算される。
メモリマップの内容は起動時にDmesgに出力されている。
メモリマップの内容は起動時にDmesgに出力されている。
空きメモリ管理に関する初期化
zone_sizes_init()
zones_size[]に各Zoneのページ数を格納
free_area_init()
free_area_init_node()
free_area_init_node()
alloc_node_mem_map()
全ページ数分+1(pgdat->node_spanned_pages + 1)の
struct pageの領域を確保してpgdat->node_mem_mapに格納
mem_map = NODE_DATA(0)->node_mem_map
free_area_init_core()
/* 各Zoneのzone構造体の初期化 */
for (j = 0; j < MAX_NR_ZONES; j++) {
:
zonetable_add()
init_currently_empty_zone()
memmap_init()
Zoneに属するpage構造体初期化
_countを0
PG_reservedをセット
virtualに0xc0000000〜の対応アドレスを格納
(HighMemは除く)
:
zone_init_free_lists()
zoneのfree_area[]を初期化
空きページ数(free_area[].nr_free)を0にする
}
[関連関数]
alloc_pages(gfp_mask, order)
2^orderページの物理ページを取得する。
gfp_maskにより、取得ページのZoneを指定したりできる。
gfp_maskにより、取得ページのZoneを指定したりできる。
config_page_data,mem_mapへのマクロ
#define NODE_DATA(nid) (&contig_page_data)
#define NODE_MEM_MAP(nid) mem_map