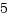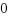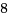動的CPU変数(percpu_counter)
percpu_counter_init()で、fbc->counterを初期化し、fbc->counters型によるインデックスからpcpu_nr_slotsまでのインデックスのpcpu_slot[]をリストヘッドとするリストされているchunk領域にアライメントを考慮した未使用領域アドレスをfbc->countersに設定し、kmemleak_alloc_percpu()でそのアドレス + __per_cpu_offset[cpu ID]にcreate_objec()でsizeの実領域を割り当てます。
struct percpu_counter {
raw_spinlock_t lock;
s64 count;
#ifdef CONFIG_HOTPLUG_CPU
struct list_head list; /* All percpu_counters are on a list */
#endif
s32 __percpu *counters;
};
int __percpu_counter_init(struct percpu_counter *fbc, s64 amount,
struct lock_class_key *key)
{
raw_spin_lock_init(&fbc->lock);
lockdep_set_class(&fbc->lock, key);
fbc->count = amount;
fbc->counters = alloc_percpu(s32);
if (!fbc->counters)
return -ENOMEM;
debug_percpu_counter_activate(fbc);
#ifdef CONFIG_HOTPLUG_CPU
INIT_LIST_HEAD(&fbc->list);
mutex_lock(&percpu_counters_lock);
list_add(&fbc->list, &percpu_counters);
mutex_unlock(&percpu_counters_lock);
#endif
return 0;
}
#define alloc_percpu(type) \
(typeof(type) __percpu *)__alloc_percpu(sizeof(type), __alignof__(type))
void __percpu *__alloc_percpu(size_t size, size_t align)
{
return pcpu_alloc(size, align, false);
}
static struct list_head *pcpu_slot __read_mostly; /* chunk list slots */
static void __percpu *pcpu_alloc(size_t size, size_t align, bool reserved)
{
static int warn_limit = 10;
struct pcpu_chunk *chunk;
const char *err;
int slot, off, new_alloc;
unsigned long flags;
void __percpu *ptr;
if (unlikely(!size || size > PCPU_MIN_UNIT_SIZE || align > PAGE_SIZE)) {
WARN(true, "illegal size (%zu) or align (%zu) for "
"percpu allocation\n", size, align);
return NULL;
}
mutex_lock(&pcpu_alloc_mutex);
spin_lock_irqsave(&pcpu_lock, flags);
if (reserved && pcpu_reserved_chunk) { -----------> reserved=FALSE
:
}
restart:
for (slot = pcpu_size_to_slot(size); slot < pcpu_nr_slots; slot++) {
list_for_each_entry(chunk, &pcpu_slot[slot], list) {
if (size > chunk->contig_hint)
continue;
new_alloc = pcpu_need_to_extend(chunk);
if (new_alloc) {
spin_unlock_irqrestore(&pcpu_lock, flags);
if (pcpu_extend_area_map(chunk,
new_alloc) < 0) {
err = "failed to extend area map";
goto fail_unlock_mutex;
}
spin_lock_irqsave(&pcpu_lock, flags);
goto restart;
}
off = pcpu_alloc_area(chunk, size, align);
if (off >= 0)
goto area_found;
}
}
spin_unlock_irqrestore(&pcpu_lock, flags);
chunk = pcpu_create_chunk();
if (!chunk) {
err = "failed to allocate new chunk";
goto fail_unlock_mutex;
}
spin_lock_irqsave(&pcpu_lock, flags);
pcpu_chunk_relocate(chunk, -1);
goto restart;
area_found:
spin_unlock_irqrestore(&pcpu_lock, flags);
if (pcpu_populate_chunk(chunk, off, size)) {
spin_lock_irqsave(&pcpu_lock, flags);
pcpu_free_area(chunk, off);
err = "failed to populate";
goto fail_unlock;
}
mutex_unlock(&pcpu_alloc_mutex);
ptr = __addr_to_pcpu_ptr(chunk->base_addr + off);
kmemleak_alloc_percpu(ptr, size);
return ptr;
fail_unlock:
spin_unlock_irqrestore(&pcpu_lock, flags);
fail_unlock_mutex:
mutex_unlock(&pcpu_alloc_mutex);
if (warn_limit) {
pr_warning("PERCPU: allocation failed, size=%zu align=%zu, "
"%s\n", size, align, err);
dump_stack();
if (!--warn_limit)
pr_info("PERCPU: limit reached, disable warning\n");
}
return NULL;
}
#ifdef CONFIG_SMP
#define per_cpu_ptr(ptr, cpu) SHIFT_PERCPU_PTR((ptr), per_cpu_offset((cpu)))
#else
#define per_cpu_ptr(ptr, cpu) ({ (void)(cpu); VERIFY_PERCPU_PTR((ptr)); })
#endif
void __ref kmemleak_alloc_percpu(const void __percpu *ptr, size_t size)
{
unsigned int cpu;
pr_debug("%s(0x%p, %zu)\n", __func__, ptr, size);
if (atomic_read(&kmemleak_enabled) && ptr && !IS_ERR(ptr))
for_each_possible_cpu(cpu)
create_object((unsigned long)per_cpu_ptr(ptr, cpu),
size, 0, GFP_KERNEL);
else if (atomic_read(&kmemleak_early_log))
log_early(KMEMLEAK_ALLOC_PERCPU, ptr, size, 0);
}
検証サンプル
#include <linux/percpu_counter.h>
struct percpu_counter babakaka;
static int __init babakaka_init(void)
{
s32 *cpu0_addr, *cpu1_addr;
percpu_counter_init(&babakaka, 1);
cpu0_addr = (s32 *)((unsigned long)babakaka.counters + (unsigned long)__per_cpu_offset[0]);
cpu1_addr = (s32 *)((unsigned long)babakaka.counters + (unsigned long)__per_cpu_offset[1]);
*cpu0_addr = 2;
*cpu1_addr = 3;
printk("sum:%d\n", (int)percpu_counter_sum_positive(&babakaka));
percpu_counter_destroy(&babakaka);
return -1;
}
module_init(babakaka_init);
結果
[root@localhost lkm]# insmod d_percpu.ko insmod: error inserting 'd_percpu.ko': -1 Operation not permitted [root@localhost lkm]# dmesg : [ 5105.822186] sum:6
補足
バージョン2.6は静的配列で定義され、countersの最大値は異なりますが、countとの関連実装はバージョン3と同じです。ただし、CPU IDはオフセットでなくcounters[]のインデックスとなります。動的にcountersを割り当てる事で、異なるCPU数システム間の運用での無駄なメモリ取得の回避と、DEFINE_PER_CPUマクロによる静的CPU変数の実装と同じする故かと理解します。バージョン2.6
#if NR_CPUS >= 16
#define FBC_BATCH (NR_CPUS*2)
#else
#define FBC_BATCH (NR_CPUS*4)
#endif
struct percpu_counter {
spinlock_t lock;
long count;
struct __percpu_counter counters[NR_CPUS];
};
static inline void percpu_counter_inc(struct percpu_counter *fbc)
{
percpu_counter_mod(fbc, 1);
}
void percpu_counter_mod(struct percpu_counter *fbc, long amount)
{
int cpu = get_cpu();
long count = fbc->counters[cpu].count;
count += amount;
if (count >= FBC_BATCH || count <= -FBC_BATCH) {
spin_lock(&fbc->lock);
fbc->count += count;
spin_unlock(&fbc->lock);
count = 0;
}
fbc->counters[cpu].count = count;
put_cpu();
}